Les expressions régulières ("regex" pour les intimes) est une syntaxe qui permet de décrire et identifier un ensemble de chaîne de caractères possibles. Quand on gère au quotidien des catalogues, inventaires ou bases de données, elles peuvent servir de super "rechercher / remplacer par" très utile pour normaliser et corriger quelques coquilles ou en masse.
 Au lieu de rechercher un mot strict (par exemple "chat"), les expressions régulières permettent de chercher des chaînes de caractères (par exemple 4 lettres, ou "c" suivi de 3 lettres, ou "c" + 2 lettres + "t"...), et si besoin de les modifier en mémorisant les valeurs initiales.
Au lieu de rechercher un mot strict (par exemple "chat"), les expressions régulières permettent de chercher des chaînes de caractères (par exemple 4 lettres, ou "c" suivi de 3 lettres, ou "c" + 2 lettres + "t"...), et si besoin de les modifier en mémorisant les valeurs initiales.
Quelques cas d'usages au quotidien quand on travaille sur des milliers de lignes :
- traquer le point final (absent ou présent, selon les choix), en fin de ligne / balise
- traquer la minuscule qui subsiste en début de champ / balise
- chercher l'année ou la date mal écrite (par exemple trois ou cinq chiffres qui se suivent)
- repérer des coquilles d'orthographes (les suivi d'un mot sans s final : les ([a-z]{3,})([a-r|t-x]) )
- etc.
Voir aussi l'article "Expression régulière" sur Wikipédia
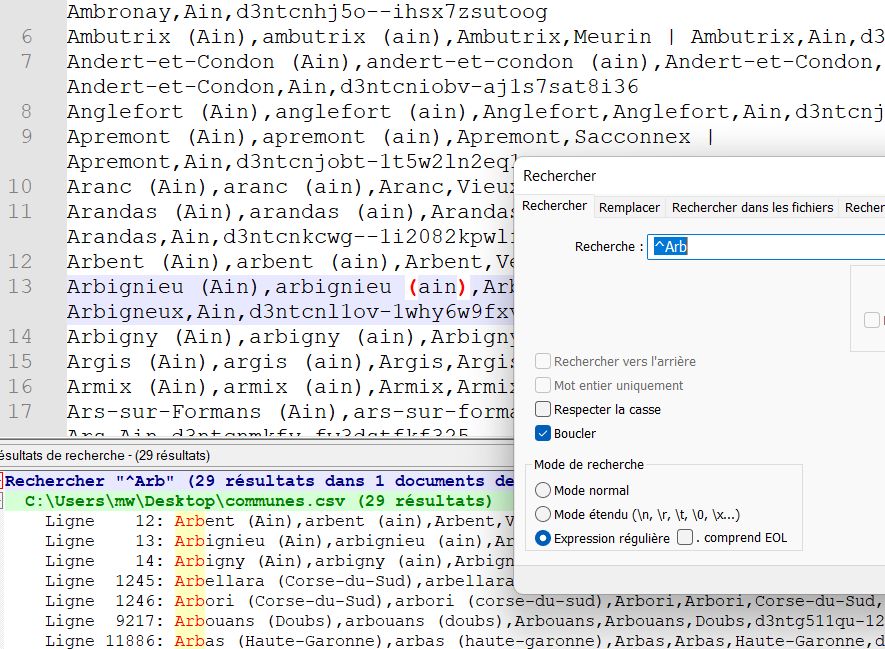 Où les utiliser ?
Où les utiliser ?
- dans les logiciels de traitement de texte (Writer, Word)
De manière plus ou moins poussée selon les logiciels, à partir de la fonction Remplacer par (control + H) et en activant l'option.
- dans les éditeurs de texte (NotePad++, EtherPad par exemple)
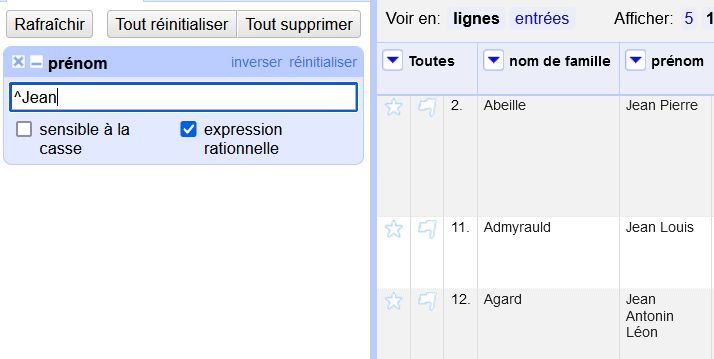
- et même dans OpenRefine
Aussi bien dans les filtres de texte que les transformations de contenu : value.replace(/^majuscule/,"Majuscule")
Pense-bête
Caractères typographiques
Chiffre : [0-9]
Lettre : [a-z]
N'importe quel caractère : . (point = joker)
Tout sauf les espaces : \S
Tout sauf un chiffre : \D
Tout sauf un caractère alpha-numérique : \W
Groupe de caractères
Toutes les minuscules : [a-z]
Toutes les majuscules jusqu'à L : [A-L]
Toutes les lettres quelle que soit leur casse : [a-zA-Z] (ou \W)
Exclure une chaîne de caractères : gr[^oai] (chaîne de caractères contenant gr suivi de tout sauf o, a ou i)
Mise en forme du texte et position
Espace : \s
Tabulation : \t
Sauf de ligne : \n
Saut de paragraphe : \r (ou $ dans LibreOffice)
Début d'une ligne : ^
Fin d'une ligne : $
Caractère d'échappement : \ (quand on veut que . signifie "point", que / signifie "slash", que ( ou ) signifie "parenthèse" , sans qu'il soit interprété comme un élément de syntaxe)
Quantificateurs
Une quantité de caractères précise : [0-9]{4} (quatre chiffres... soit une année)
Une quantité variable (mini,maxi) : [a-z]{4,8} (entre 4 et 8 lettres minuscules qui se suivent)
Une quantité variable : [A-Z]{4,} (au moins 4 lettres majuscules qui se suivent)
N'importe quelle quantité : *
Variables
Il est possible de rechercher une chaîne de caractères, la mémoriser et la réutiliser :
(chaîne-recherchée) > $1
je recherche toutes les dates sous le format JJ/MM/AAAA pour les transformer en AAAA-MM-JJ
rechercher ([0-9]{2})\/([0-9]{2})\/([0-9]{4}) > remplacer par : $3-$2-$1
(Mes) Transformations courantes
Faire une ébauche de structure CSV sur un contenu texte peu structuré : rechercher des séparateurs communs (caractère(s) qui se suivent, mots, ponctuation récurrente) et remplacer par : \t (tabulation)
Traquer les minuscules en début de cellule / balise : <unittitle.*>[a-z]
Chercher les dates cassées : [0-9]{5} ou [0-9]{3}
Changer l'affichage d'une date : rechercher ([0-9]{2})\/([0-9]{2})\/([0-9]{4}) > remplacer par $3-$2-$1 (tout de suite c'est mieux pour trier)
Chercher les points absents en fin de ligne : [^\.]$ (ou de balise [^\.]< )
Chercher les points présents en fin de ligne : \.$ (ou de balise \.< )
Mettre entre parenthèses toutes les années dans une balise (en utilisant le xpath) : rechercher : ([0-9]{4}) > remplacer par ($1)
Recherche de potentiels mots doublés (correspondance).{1,}(correspondance)
Transformer "NOM Prénom" en "NOM, Prénom" : rechercher ([A-Z][A-Z]) ([A-Z][a-z]) > remplacer par $1, $2
Par contre, les regex ne feront pas de miracle côté casse. E, É, e et é sont quatre caractères différents. Si les accents n'existent pas en majuscules, ils n'existeront pas en minuscule. Il reste toujours les recherches en masse des mots récurrents possibles (état, église, école...) et le copier-coller dans un outil de traitement de texte avec correction orthographique pour repérer rapidement ce qui est souligné en rouge.
Pour aller plus loin
- Lucas Willems, Tutoriel pour maîtriser les expressions régulières
- Zeste de savoir, Les expressions régulières
- Université Paul-Valéry Montpellier 3, Expressions régulières avec Writer, Word et Word MacOS (pour connaître leurs subtilités respectives, utiliser les cases à cocher)
Bonus archivistico-historique : traiter les exposants dans Writer (Libre Office)
(contribution d'Agnès VBB)
Objectif : mettre en exposant les dizaines (ou plus) de e pour écrire joliment XVIIe siècle
- Rechercher : (XI{0,1}V{0,1}I{0,3}e) en cochant "respecter la casse" (ça évite de transformer annexe, taxe, etc) et remplacer par $1 en sélectionner Format "exposant"
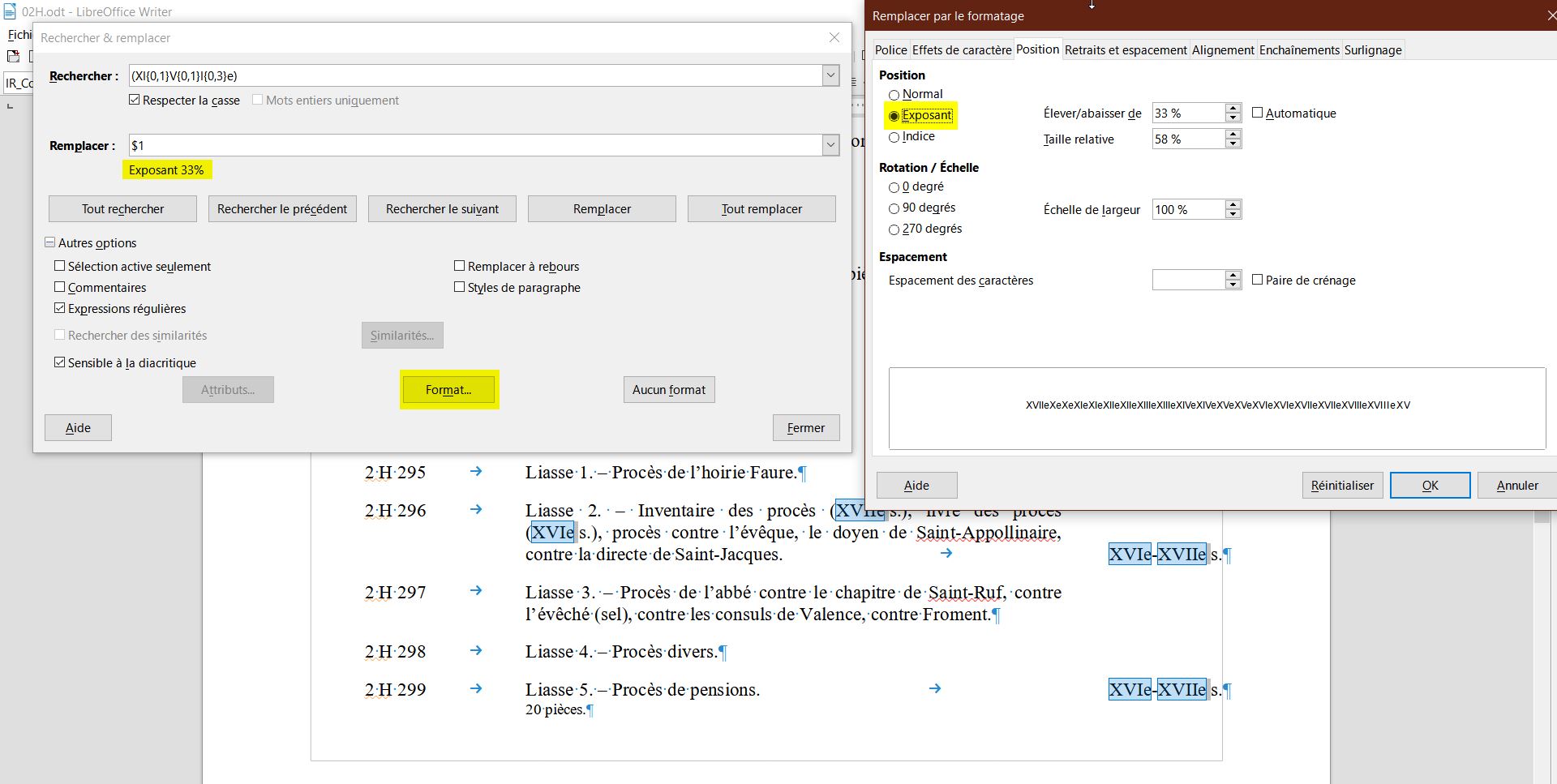
"XVIIe" est entièrement en exposant mais pas de panique, c'est normal !

- Rechercher (XI{0,1}V{0,1}I{0,3}) en sélectionnant Format "exposant" et remplacer par $1 avec Format "normal"
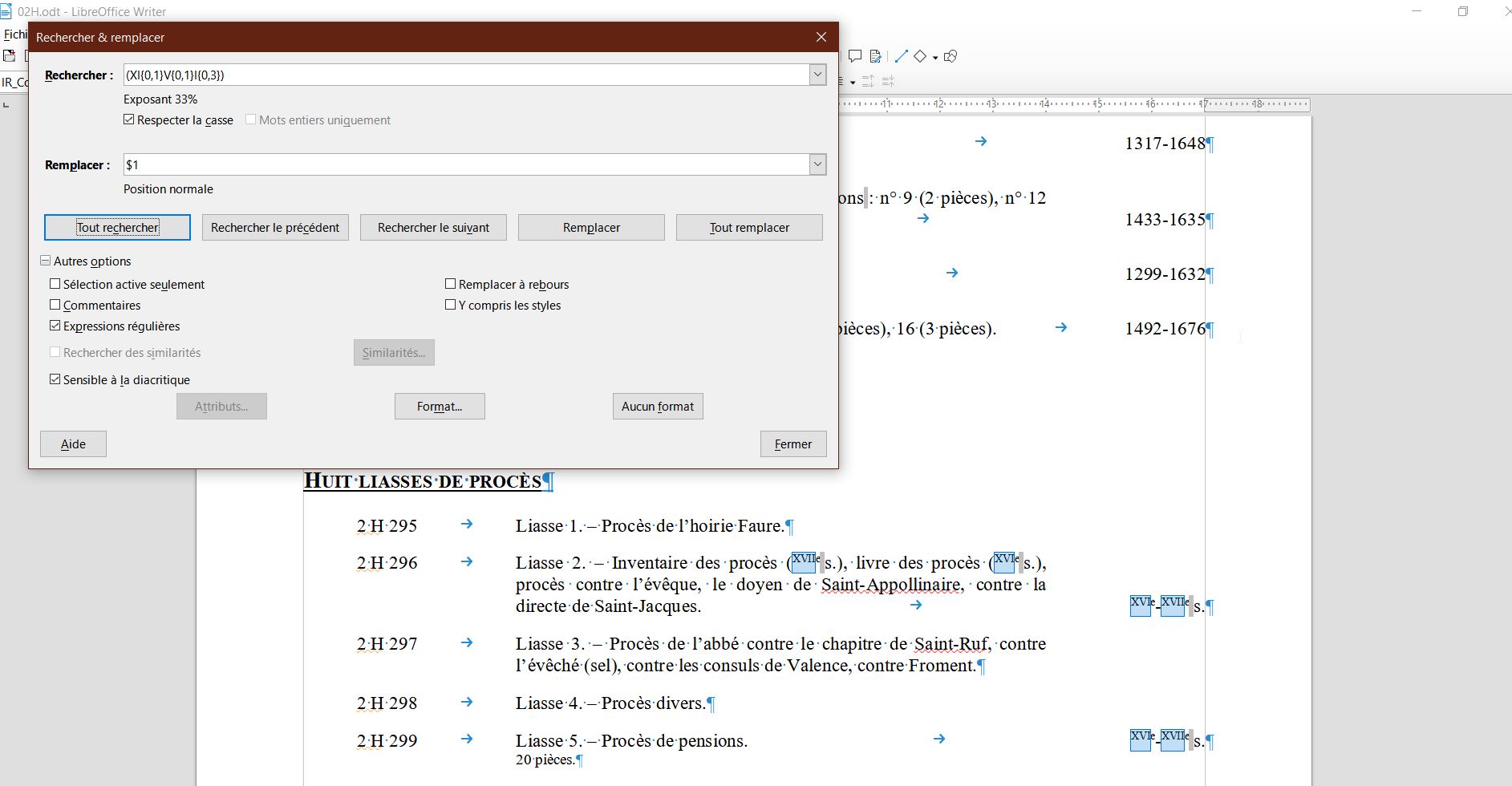
Et voici des siècles bien écrits !

Pour ceux qui cherchent les XIXe, XXe ou XXIe s., il suffit de modifier la chaîne de caractère recherchée.
Comments