#41 - Où sont les femmes ? ou comment genrer nos données patrimoniales

Cela aurait pu être une communication (non retenue) lors d'une journée d'étude... mais ça sera finalement un billet de blog. Avec un clin d'oeil pour commencer :
- Une photographie joyeuse des Archives des Bouches-du-Rhône, ainsi légendée : "Yves Montand, une divette et un journaliste, René Monduel, prennent la pose"
- Et ma réponse : "mais qui est la divette ?" (1)
La preuve par l'exemple qu'en matière de visibilisation des femmes, nos données patrimoniales font pâle figure. Quand on cherche des femmes dans les bases de données et catalogues, on peut en trouver, bien sûr, mais principalement en effectuant une recherche nominative (et encore, entre le nom d'épouse et le nom de naissance) ou en rusant sur les termes et des vocabulaires susceptibles de concerner "des femmes".
Les données c'est bête et méchant : une notice concernant Marguerite ne sortira pas en résultat de recherche "femme" s'il n'est pas précisé que Marguerite est une femme. Que faire alors pour mieux faire sortir des résultats de recherche, mais aussi améliorer la découvrabilité des contenus et rendre visible l'implicite ?
Petit retour d'expérience sur ce que je pratique dès que c'est possible lors d'opérations de rétroconversion et/ou mise en qualité de données nominatives sérielles.



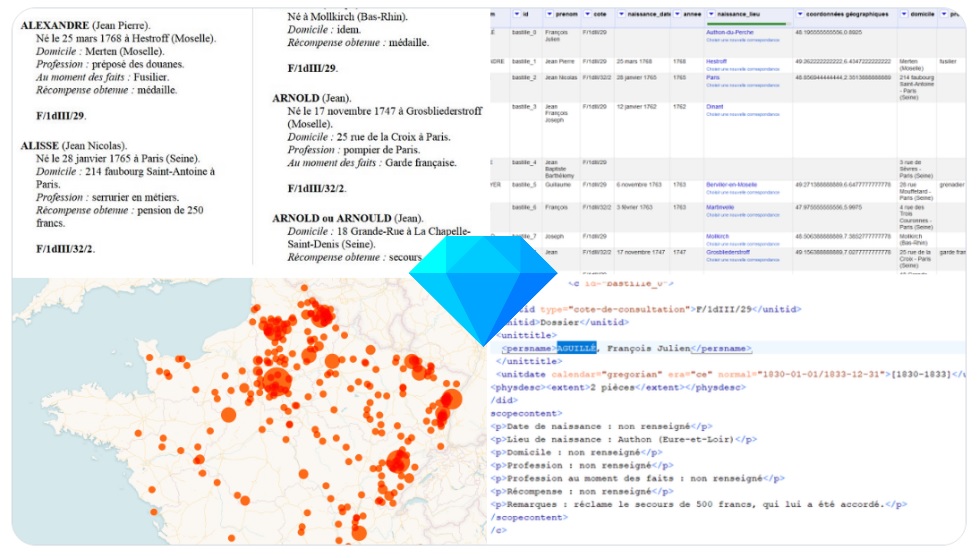 À l'occasion d'un récent encodage d'inventaire parfait pour l'exercice et après plusieurs formations partielles et expresses tronquées faute de temps, voici enfin le pas à pas illustré et détaillé du cheminement permettant de passer d'un magnifique inventaire PDF très textuel à un inventaire électronique publiable sur un portail d'archives.
À l'occasion d'un récent encodage d'inventaire parfait pour l'exercice et après plusieurs formations partielles et expresses tronquées faute de temps, voici enfin le pas à pas illustré et détaillé du cheminement permettant de passer d'un magnifique inventaire PDF très textuel à un inventaire électronique publiable sur un portail d'archives.