 À partir des années 1970, le ministère des affaires culturelles soutient des manifestations célébrant des personnages illustres ou des événements de l'histoire de France. Une délégation aux célébrations nationales est créée en 1974 sous l'impulsion du ministre des affaires culturelles Maurice Druon. Relevant d'abord de l'Association française pour les célébrations nationales, la délégation est rattachée à la direction des archives de France en 1979. La mission d'établir et piloter les célébrations (puis "commémorations") annuelle est dévolue à un "haut comité des Commémorations nationales" en 1999. La commémoration de Charles Maurras dans les commémorations en 2018 suscite une polémique, à la suite de laquelle le haut-comité démissionne. 2019 à 2021 sont des années blanches. Depuis 2022, les commémorations sont rattachées à l'Institut de France, via le service France Mémoire.
À partir des années 1970, le ministère des affaires culturelles soutient des manifestations célébrant des personnages illustres ou des événements de l'histoire de France. Une délégation aux célébrations nationales est créée en 1974 sous l'impulsion du ministre des affaires culturelles Maurice Druon. Relevant d'abord de l'Association française pour les célébrations nationales, la délégation est rattachée à la direction des archives de France en 1979. La mission d'établir et piloter les célébrations (puis "commémorations") annuelle est dévolue à un "haut comité des Commémorations nationales" en 1999. La commémoration de Charles Maurras dans les commémorations en 2018 suscite une polémique, à la suite de laquelle le haut-comité démissionne. 2019 à 2021 sont des années blanches. Depuis 2022, les commémorations sont rattachées à l'Institut de France, via le service France Mémoire.
Jusqu'au début des années 1980, la délégation des célébrations nationales soutient des initiatives d'institutions et de collectivités (expositions, colloques, concerts, édition d'ouvrages et de timbre), notamment par le biais de subventions. Un dépliant listant les célébrations est diffusé pour l'année 1985. De 1986 à 2018, un recueil annuel est édité sous la direction de la direction des archives de France puis service interministériel des archives de France. Ces ouvrages contiennent une liste d'événements et de personnalités célébrés, accompagnés d'articles rédigés, ainsi qu'une liste d'anniversaires signalés à titre d'information.
Le jeu de données créé recense les dates "officiellement" célébrées, à partir des sources suivantes :
- 1970 à 1984 : pas de "liste officielle" ; certains événements sont suffisamment conséquents pour être mentionnés dans les rapports annuels d'activité de la direction des archives de France et pour figurer dans les dossiers versés aux Archives nationales (versement 20000426). Des célébrations de cette période ne sont donc pas exhaustives mais ont été pris en compte dans le jeu de données ;
- 1985 : dépliant édité par la direction des archives de France ;
- 1986 à 2018 : sommaires des recueils édités chaque année. Les listes de dates anniversaires données à titre indicatif n'ont pas été retenues. Les ouvrages sont consultables en PDF dans les tréfonds du site archive.org (voir la colonne commentaire) et en partie sur FranceArchives pour la période 1999-2008 (Pages d'histoire) ;
- 2022 à 2024 : listes officielles diffusées par France Mémoire.
En tout 2294 événements commémorés entre 1970 et 2024. Un très grand merci à Julien, Agnès et Sylvie qui m'ont permis de combler tous les trous à partir des ressources en bibliothèque.
Notons que les célébrations puis commémorations nationales sont diffusées depuis 1995 via les réseaux numériques (Minitel, puis Internet).

La suite de ce billet est constitué de quelques visualisations de ce jeu de données (nombre d'événements, dates et périodes historiques fréquemment célébrés, individus sur-représentés, présence des femmes, couverture du territoire). Outils utilisés : OpenRefine (constitution des données et données statistiques), Flourish et LibreOffice Calc.









 Le 4e forum des archivistes français se tient à Rennes du 26 au 28 mars 2025. Plus de 1000 archivistes ou archives-friendly* réunis pour un programme de conférences, ateliers et tables-ronds autour du thème "Avec attention - archives, archivistes et sociétés".
Le 4e forum des archivistes français se tient à Rennes du 26 au 28 mars 2025. Plus de 1000 archivistes ou archives-friendly* réunis pour un programme de conférences, ateliers et tables-ronds autour du thème "Avec attention - archives, archivistes et sociétés". 
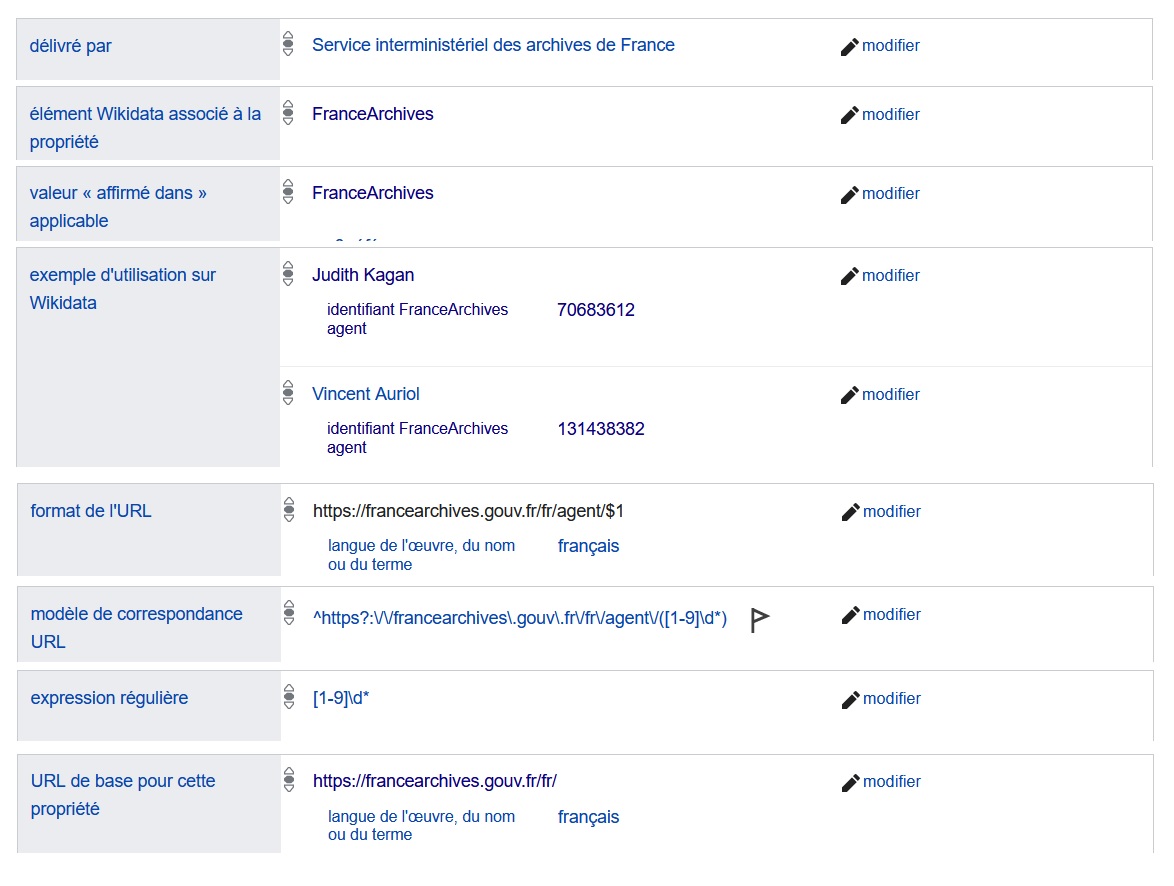
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}